简明扼要的Python爬虫思路,并有一个简单的例子。
问题的本质
记我们在某个网页上感兴趣的信息为$I_0$。我们需要做的就是获取信息$I_1$,使得通过一个请求$R_0$,我们可以由$I_1$得到$I_0$。听起来简单,但这里有几个地方会变得复杂:
- 多数情况下这个问题是递归的,即$I_i$的获取依赖于包含信息$I_{i+1}$的请求$R_i$,此处$i$是非负整数,直到某个信息$I_k$是我们掌握的原始信息。当然严格来说,信息的依赖关系也可能呈一个有向无环图。
- 我们需要将一个信息进行解析或变形才能将其应用于下一个请求或作为我们想要的结果。
- 反爬手段,例如验证码,会试图阻止自动化请求的顺利进行。
确定请求
根据上面的讨论,我们可以不严谨地得到一个结论:除非有网站上有非常困难的验证码,人类通过浏览器访问网页能获取的信息,爬虫都可以获取。这里的关键就是如何通过$I_i$确定请求$R_i$的格式及其包含的信息$I_{i+1}$。所用方法叫做抓包。 打开火狐浏览器的隐私浏览模式(为了消除以前的浏览缓存可能导致的问题),按下F12进入开发者模式,打开Network Monitor,然后用人类的方法打开待爬的网站。浏览器会记录所有和服务器的通信包。 现在按下Ctrl+Shift+F,就可以在所有请求中进行搜索。我们把$I_i$中足够长的一段文本作为关键词搜索,就(比较有希望)找到获取到$I_i$的那个请求了。观察一下整个请求的详细信息,如果确定找到了,右击它,选择Copy - Copy as cURL,然后粘贴到这个项目,就可以自动将cURL请求转换成Python代码。然后试着弄明白请求的每个参数都是怎么来的,问题就被递归地化解了。 下面是一些讨论。
搜不到某个请求怎么办?
- 尝试其他的关键词。
- 信息可能被预处理过。例如尝试常见的加密方案,如Base 64.
- 逐个排查所有可能的请求。
需要使用Cookies怎么办?
在进行多个请求,需要记录Cookies的情形下(如需要登录帐号)记得用requests库的session来实现。
响应信息的解析
静态网页和动态网页,对于爬虫来说本质区别在于信息传输的格式。静态网页是服务器渲染好了HTML再返回到浏览器,而动态网页是服务器直接传JSON或者XML等纯数据格式给浏览器。爬取方式讨论如下:
- JSON/XML等。因为JSON或者XML的信息往往是结构性很强的,用Python相应的库解析即可。
- 对于HTML的解析,可以用
beautifulsoup等库的parser,然后通过元素的tag name/class name/attributes或元素之间的相对位置来确定信息所在元素,然后把需要的信息提出来。
这都是最理想的讨论。实际情况中,你可能遇到任何一种你想的到的数据传输方式。例如:
- 有些网站会把信息写成JavaScript的数组赋值代码,这种情况或者采用正则表达式,或者采用eval代码的方式模拟浏览器。
- PDF格式的数据。一般不是很规则,可以考虑用
PyPDF2等库解析一下。 - Excel工作簿或csv等。考虑
openpyxl或pandas等库。
不一而足。这就要具体问题具体分析了。
常见反爬手段
- 通过浏览器UA反爬。这个非常容易,改headers即可。当然,按刚刚的方法,从浏览器中复制并用这个项目生成的Python代码本身是带UA伪装的。
- IP请求数量限制。一种方法是随机生成X-Forwarded-For来欺骗服务器,不过这个可能失效;另一种方法就是走代理,不过这显然需要你有一定数量的代理换着用;当然还有一种方法就是降低请求频率。
- 验证码。有些验证码机器是没法突破的,但也有很多验证码机器都是可以识别出来的,例如可以考虑图像预处理并OCR等方法。
另一种思路
用Selenium库就是完全在模拟人类在浏览器的操作(点击、输入、拖动等)。可以配合Chrome/Firefox操作,也可以用无头浏览器。 好处:
- 允许人类介入,如进行验证码输入。
- 不太用关心请求层面的问题。
坏处:
- 每次运行都非常慢,因为要加载网页的所有元素。
- 网页结构发生细微变化,爬虫都可能失效。
一个例子
给定题目编号(如HDU-1079),爬取Virtual Judge上题目的样例输入。 首先随便找一个题目https://vjudge.net/problem/HDU-1079打开,并检测网络请求。 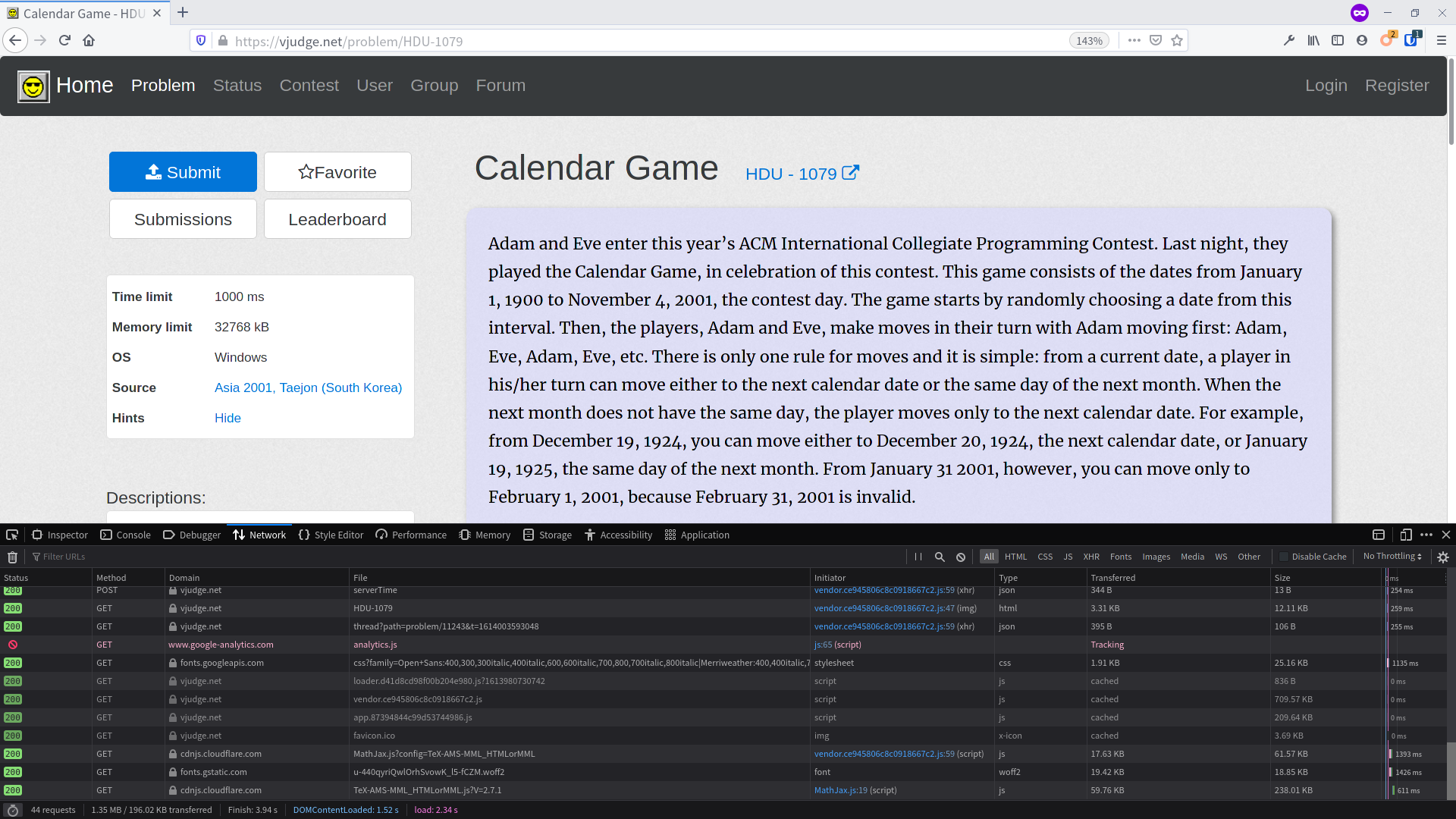 我们感兴趣的数据是
我们感兴趣的数据是
1 | 3 |
拿2001 11 3作为关键字在所有请求中搜索: 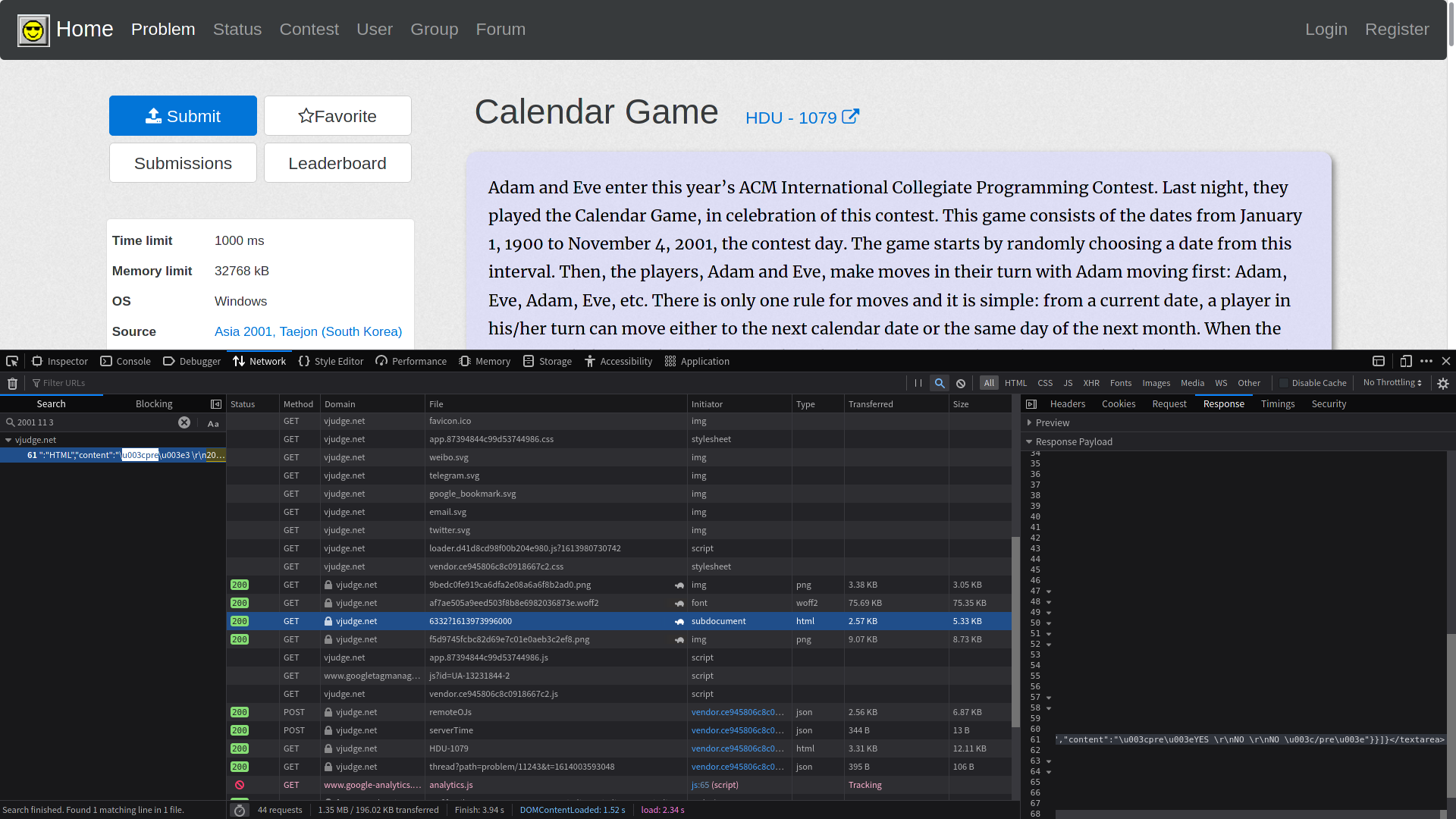 有一个请求的响应有这个关键字,它是
有一个请求的响应有这个关键字,它是GET https://vjudge.net/problem/description/6332?1613973996000=。当然我们发现这个网页本身可以打开,是一个纯的题目描述网页。下面我们就需要得到6332和1613973996000这两个参数是怎么来的。搜索1613973996000,原来就是在GET https://vjudge.net/problem/HDU-1079#中就包含这个参数。整体的思路就很清晰了,下面就是数据解析的问题。 发现在请求GET https://vjudge.net/problem/HDU-1079#中,需要的信息在这一段HTML中:
1 | <li class="list-group-item"> |
这里有很多方法,其中一种是先找到那个li,然后再找到它下面的a,再提出其中的data-id和data-version即可。注意到li是网页中第一个class为list-group-item的,故可以写:
1 | def vjudge_scraper(problem_id): |
这样两个需要的参数就得到了。再在请求GET https://vjudge.net/problem/description/6332?1613973996000=中,注意到所要信息在这段HTML中(有删节):
1 | <textarea class="data-json-container" style="display: none">{"trustable":true,"sections":[{"title":"","value":{"format":"HTML","content":"\u003cscript type\u003d\u0027text/x-mathjax-config\u0027\u003eMathJax.Hub.Config({tex2jax: { inlineMath: [[\u0027$\u0027,\u0027$\u0027]] } }); \u003c/script\u003e\n\u003cscript type\u003d\u0027text/javascript\u0027 src\u003d\u0027https://cdnjs.cloudflare.com/ajax/libs/mathjax/2.7.1/MathJax.js?config\u003dTeX-AMS-MML_HTMLorMML\u0027\u003e\u003c/script\u003e\n\u003cscript type\u003d\u0027text/javascript\u0027\u003esetTimeout(function(){MathJax.Hub.Queue([\u0027Typeset\u0027, MathJax.Hub, \u0027left_view\u0027]);}, 2000);\u003c/script\u003e\n\u003cdiv class\u003d\"panel_content\"\u003e\n Adam and Eve enter this year’s ACM International Collegiate Programming Contest. \u003cbr\u003e\n\u003c/div\u003e"}},{"title":"Input","value":{"format":"HTML","content":"The input consists of T test cases.\n\u003cbr\u003e"}},{"title":"Output","value":{"format":"HTML","content":"Print exactly one line for each test case.\n\u003cbr\u003e"}},{"title":"Sample Input","value":{"format":"HTML","content":"\u003cpre\u003e3 \r\n2001 11 3 \r\n2001 11 2 \r\n2001 10 3 \u003c/pre\u003e"}},{"title":"Sample Output","value":{"format":"HTML","content":"\u003cpre\u003eYES \r\nNO \r\nNO \u003c/pre\u003e"}}]}</textarea> |
先解析HTML找到tag是textarea的第一个元素,然后发现里面的内容是个JSON,再对JSON进行解析,但JSON的对应的value又是个HTML,再次解析即可。
1 | def vjudge_scraper(problem_id): |
到这里写出来的程序对于一部分题目(如HDU的题目)是可以爬取的,但有些题目的样例输入格式有些不同,这样写会导致错误,例如CodeForces的题目,在网页上呈现出的输入格式就有差异。对于这些差异需要再进行一些判断和另外的处理,故上面一段代码改为:
1 | def vjudge_scraper(problem_id): |
这样就可以适配更多的题目格式了。但依然有问题,比如UVa的题目是PDF格式的,那么如果要做爬虫的话就需要解析PDF,这就是另一个故事了。